The Effects of Latency on WAN Speed
So, what are the effects of latency on WAN speed and what are the typical values? What causes it and why is it important? Why does it differ from network to network? Let’s review the basics:
Latency is a measure of delay. In a network, latency measures the time it takes for some data to get to its destination across the network. It is usually measured as a round trip delay – the time taken for information to get to its destination and back again. The round trip delay is an important measure because a computer that uses a TCP/IP network sends a limited amount of data to its destination and then waits for an acknowledgement to come back before sending any more. Thus, the round trip delay has a key impact on the performance of the network. Additionally, latency is usually measured in milliseconds (ms). (read full article here).
Each hop (or jump) a packet takes from router to router across the WAN increases latency time. Storage delays can occur when a packet is stored or accessed resulting in a delay caused by intermediate devices like switches and bridges.

Many people have likely heard the term latency being used before but of misunderstand the true definition? In terms of network or WAN latency, this can be defined by the time it takes for a request to travel from the sender to the receiver and for the receiver to process that request. Again, the round trip time from the browser to the server. It is obviously desired for this time to remain as close to 0 as possible, however, there can be a few things at play preventing your website latency times to remain low.
Latency vs bandwidth vs throughput
Although latency, bandwidth, and throughput all work together hand-in-hand, they do have different meanings. It’s easier to visualize how each term works when referencing it to a pipe:
- Bandwidth determines how narrow or wide a pipe is. The narrower it is, the less data is able to be pushed through it at once and vice-versa.
- Latency determines how fast the contents within a pipe can be transferred from the client to the server and back.
- Throughput is the amount of data which can be transferred over a given time period.
If the latency in a pipe is low and the bandwidth is also low, that means that the throughput will be inherently low. However, if the latency is low and the bandwidth is high that will allow for greater throughput and a more efficient connection. Ultimately, latency creates bottlenecks within the network thus reducing the amount of data which can be transferred over a period of time. (read more about WAN latency here).
Causes of network latency
The effects of latency on WAN speed can be crippling. The question of what is latency has been answered, now where does latency come from? There are 4 main causes that can affect network latency times. These include the following:
- Transmission mediums such as WAN or fiber optic cables all have limitations and can affect latency simply due to their nature.
- Propagation is the amount of time it takes for a packet to travel from one source to another (at the speed of light).
- Routers take time to analyze the header information of a packet as well as, in some cases, add additional information. Each hop a packet takes from router to router increases the latency time.
- Storage delays can occur when a packet is stored or accessed resulting in a delay caused by intermediate devices like switches and bridges.
Ways to reduce latency
Latency can be reduced using a few different techniques as described below. Reducing the amount of server latency will help load your web resources faster, thus improving the overall page load time for your visitors.
- AI or Artificial Intelligence – Technologies that accelerate data transfers and eliminate data management challenges are known as ‘WAN acceleration’. Bridgeworks patented AI technologies accelerate your existing technologies and dramatically accelerates your WAN, dramatically improving data throughput by up to 98% of bandwidth – regardless of distance. Artificial intelligence underpins the patented technology to provide process intelligence, reduced latency and mitigation of packet loss resulting in rocket speed transfers all being managed in real time by AI. (learn more about AI WAN Acceleration here) or call (800) 278-3480 to speak to a WAN acceleration specialist today.
- HTTP/2: The use of the ever prevalent HTTP/2 is another great way to help minimize latency. HTTP/2 helps reduce server latency by minimizing the number of round trips from the sender to the receiver and with parallelized transfers. KeyCDN proudly offers HTTP/2 support to customers across all of our edge servers.
- Fewer external HTTP requests: Reducing the number of HTTP requests not only applies to images but also for other external resources such as CSS or JS files. If you are referencing information from a server other than your own, you are making an external HTTP request which can greatly increase website latency based on the speed and quality of the third party server.
- Using a CDN: Using a CDN helps bring resources closer to the user by caching them in multiple locations around the world. Once those resources are cached, a user’s request only needs to travel to the closest Point of Presence to retrieve that data instead of going back to the origin server each time.
- Using prefetching methods: Prefetching web resources doesn’t necessarily reduce the amount of latency per se however it improves your website’s perceived performance. With prefetching implemented, latency intensive processes take place in the background when the user is browser a particular page. Therefore, when they click on a subsequent page, jobs such as DNS lookups have already taken place, thus loading the page faster.
- Browser caching: Another type of caching that can be used to reduce latency is browser caching. Browsers will cache certain resources of a website locally in order to help improve latency times and decrease the number of requests back to the server. Read more about browsing caching and the various directives that exist in our
Cache-Controlarticle.
Other types of latency
Latency occurs in many various environments including audio, networks, operations, etc. The effects of latency on WAN speed can be seen anywhere data flows. The following describes two additional scenarios where latency is also prevalent.
Fibre optic latency
Latency in the case of data transfer through fibre optic cables can’t be fully explained without first discussing the speed of light and how it relates to latency. Based on the speed of light alone (299,792,458 meters/second), there is a latency of 3.33 microseconds (0.000001 of a second) for every kilometer of path covered. Light travels slower in a cable which means the latency of light traveling in a fibre optic cable is around 4.9 microseconds per kilometer.
Based on how far a packet must travel, the amount of latency can quickly add up. Cable imperfections can also degrade the connection and increase the amount of latency incurred by a fibre optic cable.
Audio latency
This form of latency is the time difference between a sound being created and heard. The speed of sound plays a role in this form of latency which can vary based on the environment it travels through e.g solids vs liquids. In technology, audio latency can occur from various sources including analog to digital conversion, signal processing, hardware / software used, etc.
How to measure network latency?
Network latency can be tested using either Ping, Traceroute, or MTR (essentially a combination of Ping and Traceroute). Each of these tools is able to determine specific latency times, with MTR being the most detailed.
The use of MTR allows a user to generate a report that will list each hop in a network that was required for a packet to travel from point A to point B. The report will include details such as Loss%, Average latency, etc. See our traceroute command article to learn more about MTR and traceroute.
Essentially, latency is measured using one of two methods:
- Round trip time (RTT)
- Time to first byte (TTFB)
The round trip time can be measured using the methods above and involves measuring the amount of time it takes between when a client sends a request to the server and when it gets it back. On the other hand, the TTFB measure the amount of time it takes between when a client sends a request to a server and when it receives its first byte of data. You can use our performance test tool to measure the TTFB of any asset across our network of 16 test locations.
What are typical values for latency?
Typical, approximate, values for latency that you might experience include:
- 800ms for satellite
- 120ms for 3G cellular data
- 60ms for 4G cellular data which is often used for 4G WAN and internet connections
- 20ms for an mpls network such as BT IP Connect, when using Class of Service to prioritise traffic
- 10ms for a modern Carrier Ethernet network such as BT Ethernet Connect or BT Wholesale Ethernet in the UK
Why is latency important?
People often assume that high performance comes from high bandwidth, but that’s not a full picture.
- The bandwidth of a network or a network circuit refers to its capacity to carry traffic. It is measured in bit per second; commonly Megabits per second (Mbps).
- A higher bandwidth means that more traffic can be carried; for example, more simultaneous conversations. It does not imply how fast that communication will take place (although if you attempt to put more traffic over a network than the available bandwidth, you’ll get packets of data being discarded and re-transmitted later, which will degrade your performance).
Latency, on the other hand, refers to the length of time it takes for the data that you feed into one end of your network to emerge at the other end. Actually, we usually measure the round trip time; for data to get to one end, and back again.
Why is it important to count the time in both directions?
Well, as we’ll see below, TCP sends acknowledgement bits back to the sender, and it turns out, that this is critical.
- It’s fairly intuitive that a bigger delay means a slower connection.
- However, due to the nature of TCP/IP (the most widely used networking protocol), latency has a more complex and far reaching impact on performance: latency drives throughput.
Latency drives throughput
A network typically carries multiple simultaneous conversations.
- Bandwidth limits the number of those conversations that can be supported.
- Latency drives the responsiveness of the network – how fast each conversation can be had.
- For TCP/IP networks, latency also drives the maximum throughput of a conversation (how much data can be transmitted by each conversation in a given time).
Latency can become a particular problem for throughput because of the way TCP (Transmission Control Protocol) works.
TCP is concerned with making sure all of the packets of your data get to their destination safely, and in the correct order. It requires that only a certain amount of data is transmitted before waiting for an acknowledgement.
Imagine a network path is a long pipe filling a bucket with water. TCP requires that once the bucket is full, the sender has to wait for an acknowledgement to come back along the pipe before any more water can be sent.
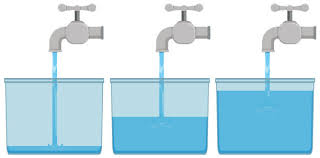
In real life, this bucket is usually 64KB in size. That’s 65535 (ie 2^16) x 8 = 524,280 bits. It’s called the TCP Window.
Let’s imagine a scenario in which it takes half a second for water to get down the pipe, and another half a second for the acknowledgement to come back … a latency of 1 second.
In this scenario the TCP protocol would prevent you from sending any more than 524,280 bits in any one second period. The most you could possibly get down this pipe is 524,280 bit per second (bps) – otherwise expressed as half a megabit per second.
Notice that (barring other issues that may slow things down) the only thing driving this is latency.
Max throughput can never be more than the bucket size divided by the latency.
So how does latency impact throughput in real life?
Clearly, if you have latency-sensitive applications then you need to be mindful of the latency of your network. Look out for situations where there might be unexpectedly excessive latency that will impact throughput. For example, international circuits.
Another interesting case is with 4G Cellular WAN, where one uses the 4G network to create a reliable, high speed connection to your corporate network, or to the internet. This involves the use of multiple SIMs that are often bonded together into a single, highly reliable connection. In this case, the latency of the bonded connection tends towards the greatest latency of all the individual connections.
If you consider the difference between 3G and 4G in the list above, you’ll see that including 3G connections can have a big impact on the overall latency. Read more about 4G WAN in our Guide to 4G WAN.
Remember, though, that latency is not the only cause of poor application performance. When we researched the root cause of performance issues in our customers’ networks, we found that only 30% were caused by the network. The other 70% were caused by issues with the application, database or infrastructure. To get to the bottom of such problems, you often need an Application Performance Audit, or perhaps to set up Critical Path Monitoring on your IT estate. Generally, you’ll track latency and other performance-impacting indicators using a Network and Application monitoring toolset. See this post for more on building the best managed network provider monitoring.
Solving the effects of latency on WAN speed
Here at Rapid Data Transfer, we completely sidestep the latency issue – the effects of latency on WAN speed – by utilizing patented AI technology to provide process intelligence. Simply put, we reduce latency and mitigation of packet loss resulting in rocket speed transfers across the WAN. Call for a free demo today and see how you can maximize throughput up to 98% of bandwidth. CALL (800) 278-3480 to speak to a Data Acceleration specialist.
Recent Comments